Version Control, even distributed, isn't hard if you factor it right
diff tools: ~360 LOC
graph utilities: ~40 LOC
DVCS code: ~420 LOC
time spent: three Saturday afternoons
Version Control can seem jolly difficult if you tangle all
the pieces together (CVS, SVN, ...)
Merging is the most important bit for correctness; storage design
is important for usability
Little Unix-style composable tools are the way to go (but user
interface is also very important)
Modern DVCSs factor apart networking, synchronisation, history,
storage, and merging; older VCSs tangled them all together, which
led to much implementation and conceptual complexity.
Basic Algorithms
Diff and patch
can be used for resolution (= the process of deciding what the user did to a file)
can be used to compress multiple stored versions
"two-way merge"
Diff3, a 3-way merge algorithm
used for history-sensitive textual merge
other merge algorithms exist; some are better!
Least Common Ancestor
used to find the most appropriate ancestral revision to use in a merge
Diff
Longest Common Subsequence
hello,worldhead cold
Diff produces a delta (a.k.a. "patch", "hunk", "chunk", "diff")
diff uses a Longest Common Subsequence algorithm to
find a short description of the differences between two files. The
notion of minimum edit distance is a related idea.
It so happens that the output of diff often makes sense to
a human trying to figure out how a file has been changed. How lucky!
Note that Diff.diff_patch can operate equally well on lists
of strings an on lists of characters (strings). It doesn't work very
well when given single strings, as in the example above, but it does
work.
Sometimes called two-way merge: every difference is a conflict
Bram Cohen has
invented a diff algorithm that works well for
programming-language (or other line-oriented) text. It uses uniquely
occurring lines to anchor the LCS.
In some revision-control systems, e.g. darcs, inverting a patch is a
central operation. Darcs in particular has a full (and very useful!)
"theory of patches", where patch inversion, commutation and merging
are developed formally.
Variations
Diff.diff_comm - works like a simple Unix comm(1)
Diff.diff_patch - works like a simple Unix diff(1)
Diff.invert_patch - inverts a patch produced by diff_patch
Diff.patch - works like a (very) simple Unix patch(1)
Diff.diff_indices - like diff_patch, but only gives offset and length information
Diff Demo
Diff3 and Three-Way Merging
History-sensitive merge
Some changes are conflicts; others are not
Automatically smart about which is which, in a fairly understandable and predictable way
var base =
"the quick brown fox jumped over a dog".split(/\s+/);
var derived1 =
"the quickfox jumps over some lazy dog".split(/\s+/);
var derived2 =
"the quick brown fox jumps over some record dog".split(/\s+/);
var mergeResult = Diff.diff3_merge(derived1, base, derived2, true);
/* [{ok:["the", "quick","fox", "jumps", "over"]},
{conflict:{a:["some", "lazy"], aIndex:5,
o:["a"], oIndex:6,
b:["some", "record"], bIndex:6}},
{ok:["dog"]}] */
Diff3 Demo
Least Common Ancestor
LCA is defined for trees. Efficient algorithms are known to
exist. It has also been defined for DAGs, which is the case we have
in a DVCS, but the definition leads to some problems in our case.
DVCS Components
History
ancestry DAG
Merging
choosing an ancestor
conflict detection and handling
Synchronisation
copying history between repositories
network transfer, file system, ...
Storage
of file versions
of changesets/patches
History
History is a DAG of changesets.
Each changeset should record
Its own unique identity (a UUID)
Which specific versions of files are alive, with their paths and metadata
Which files are dead (deleted)
IDs of parent changeset(s)
Timestamp, comment, committer, ...
Many modern DVCSs use some function of the contents of an object to
identify the object, e.g. a SHA-1 hash. This has a lot of nice
properties, and is a good choice. JavaScript doesn't have
particularly good support for binary data, which makes hashing (and
canonical binary representations!) awkward, so I chose to use simple
random UUIDs for identifiers, instead.
History
Merging
Resolution step
Merge step
Deciding what makes a good merge algorithm is an actively researched area
DieDieDieMerge
Synchronisation
What do you know that I do not? ("pull")
What do I know that you do not? ("push")
Updating a working-copy is a separate operation (a merge)
Can synchronise using any transport or representation that can
inform others about the revision IDs it holds
export revisions and their contents in a standard form
import revisions submitted to them in standard form
Storage
The database used to store all information about current and past
state in the repository, in every branch, for every commit.
Design storage around query patterns: user interface is central
Design for efficient synchronisation with other repositories
Finally, efficient use of disk space can be important, too (less and less as time goes by)
Storage
Narrow API - interface to merging, synchronisation, history is fairly simple
Can store full snapshots, or deltas from newer to older versions, or both, as required
tradeoff space/speed/convenience
Mercurial does well here: deltas, with periodic snapshots when
deltas grow too large, giving O(1) arbitrary version retrieval
Storage
Example user-interface-led design criteria:
retrieving an old version of a single file should be fast
retrieving snapshots of old versions of the whole repository should be fast
retrieving history for a single file or the whole repository should be fast
avoid dragging in too many unrelated records when performing
single-file operations (think Wikipedia-scale system: how to
avoid querying the whole repo when viewing a single page?)
DVCS Demo
The End
Any questions?
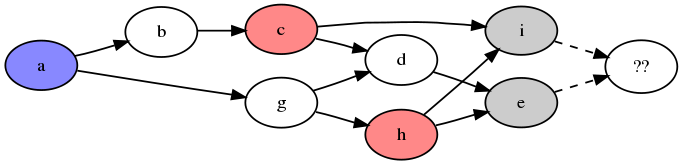
Ambiguous LCA
Here's a problem case. The LCA of "e" and "i" is either "c" or
"h". Both "c" and "h" are two steps away from the root.
Note that the path from "e" to "i" through "c" is three steps long,
while the path through "h" is two steps long. This could mean that
"h" is a more suitable ancestor for use in 3-way merging.
The algorithm I've implemented is very naive and inefficient. It
also answers "c" or "h" depending on the order of arguments you give
it.
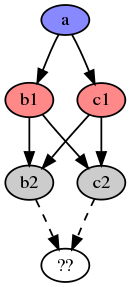
Criss-cross Merge
Truncating History
Can truncate, missing piece may be held by other servers, or can
fall back to two-way merge